

Running Dask in the cloud is easy.
Running Dask in the cloud securely is hard.
Running Dask for an enterprise in the cloud is really hard.
Over the last couple of years, Coiled has made a cloud-SaaS application that runs Dask for folks smoothly and securely in the cloud.
We thought you would like to hear a bit about the choices we made and why.
Coiled had three main objectives when making our design:
This led us down a path of a cloud SaaS application with:
We felt that this was the best choice to enable scalable Python for the most people in a way that we could execute on with a small team. We’re pretty happy with the result.
There are lots of excellent paths here that make sense, but that we chose not to pursue. For example:
These are all great choices, and target different kinds of users.
Coiled is a web application that manages cloud resources within user accounts on their behalf. You give us highly restricted access to your cloud. Members of your team then ask for Dask clusters, and we set up those Dask clusters for them on the fly.
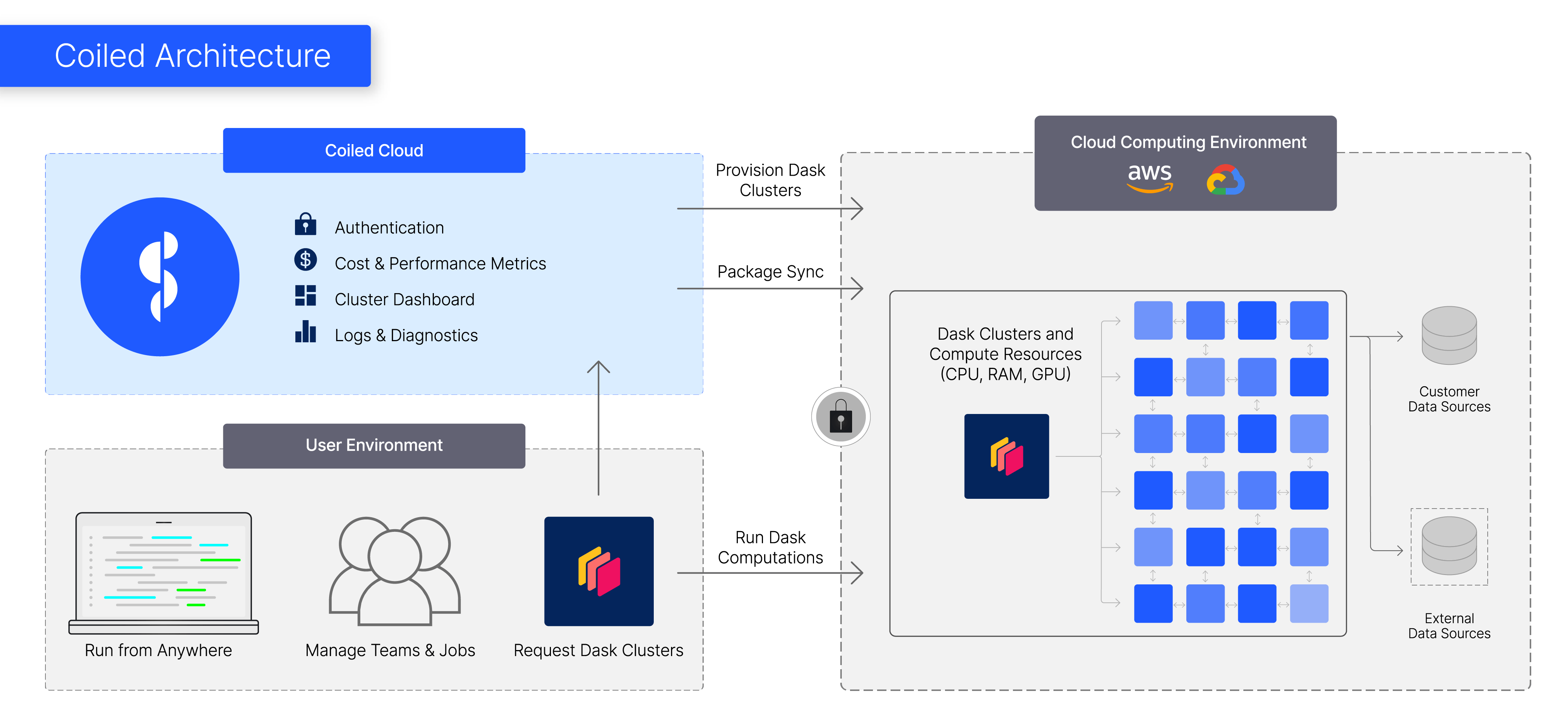
We’ve found that this approach provides a good balance of giving users the data security that they need while letting us iterate very quickly on the product and so provide a better user experience. It’s a little nuanced though, let’s dig in a bit.
First, let’s go through how we coordinate cloud access safely to set up resources for users.
As a user you need to to give Coiled enough permissions to do things like:
This is done once and then the Coiled web app has these permissions until you revoke them. Notably, you don’t give any permission to read and write from sensitive data sources like cloud object stores, Snowflake, and so on. All Coiled can really do is run up your cloud bill.
Then when users ask for a Dask cluster
Coiled looks up your credentials, creates the necessary infrastructure, creates trusted security tokens, and gives those tokens to either side so that the user can then connect directly from their system to that cluster.
Coiled sets up infrastructure, brokers a secure connection between the user and that infrastructure, and then gets out of the way as quickly as possible.
The user then has access to a Dask cluster without Coiled acting in the middle. This is great. The user then sends data access credentials from their machine up to the Dask cluster. This allows the cluster to access sensitive data resources within the company without Coiled itself ever seeing the data or the credentials.
The result is that anyone on your team can quickly get access to a fully authenticated and secure Dask cluster that can access all of the data that they have access to in a minute or two.
Let’s talk a bit about how we actually set up and deploy resources.
To actually create the Dask scheduler and worker processes Coiled uses raw instances. This is in contrast to other options like using Kubernetes or container-as-a-service options like AWS Fargate.
Kubernetes is great. We love Kubernetes here at Coiled, but it also introduces complexity that we actually don’t need to accomplish our goals. Also, removing the intermediate layer of Kubernetes allowed us to develop a product that was more flexible and raw-metal.
Instead, we use technologies like EC2 fleets so that we could easily adapt to our customers' many varied workloads with often very different hardware requirements. Once we have a bunch of VMs at our disposal we need to install just the right versions of Python packages on them. This can be tricky.
In order for Dask to work well, the versions of software libraries need to match exactly between where Coiled/Dask is invoked, and the workers that are run in the cloud. We do this in two ways (learn more in our documentation):
This works well, but can get a bit finicky especially when the user’s environment changes rapidly. Adding a conda solve and docker build step into development cycles causes a lot of slowdown and pain.
2. We dynamically query the user’s local environment and install those packages on-the-fly This is far more magical, but works pretty well:
When something breaks users often want to go and look at logs. Where should these logs go?
As always, Coiled tries hard not to store anything from the user, and instead rely on cloud-native solutions. This means that for AWS we store user logs in CloudWatch, and for Google Cloud we store user logs in Google Cloud Logging. We provide easy methods to query these logs, but they are also easily accessible from however the user already handles logs within their organization.
As always, Coiled tries to be convenient, but not intrusive.
Finally, Coiled also acts as a watchdog over your Dask processes. If a cluster has been idle for too long we’ll kill it. If a user is launching GPU resources and not using them, we make folks aware of it. Gathering usage information is key.
To accomplish this, Coiled installs a SchedulerPlugin in the Dask schedulers that tracks various usage metrics like idleness, which operations are running, etc. This information is really useful for debugging and cost optimization, but can also be somewhat invasive. We allow users to turn various bits of this data tracking on and off with configuration (see the Coiled documentation on analytics).
Coiled is free for the first 10,000 CPU hours a month (although you still have to pay your cloud provider). Beyond that we charge $0.05 per managed CPU hour, with rates that decline based on usage.
We’ve found that this is enough for individuals to operate entirely for free, and for folks at larger organizations to “try before they buy” pretty effectively. For companies who do spend thousands of dollars or more per month, we look comparable to services like Databricks or SageMaker. Especially when compared against the personnel cost of building and maintaining a system like Coiled, this very obviously becomes worth the cost.
Anyone with a cloud account can connect their accounts to Coiled in a couple of minutes, and can be scaling happily afterwards, knowing that they’re secure. Our development teams have enough information to see what’s going on to rapidly iterate on a better user experience, while users can rest assured that both their data and budgets are safe and secure. For a more details, see Why Coiled?.
If you’re interested, Coiled is easy to try out. Just run the following in any Python-enabled environment after you've created a Coiled account:




