Process Large Datasets with Polars
Query 150GB of data in the cloud without managing infrastructure
Introduction#
Local machines often struggle with large datasets due to memory and network limitations. This example shows how to process a 150 GB dataset in minutes using Coiled Functions and Polars.
The calculation processes 150 GB of data in around 7 minutes, costing approximately $0.50. You can run it right now. You'll need the following packages:
pip install polars s3fs coiled
pip install polars s3fs coiled
Full code#
Then run this. If you're new to Coiled this will run for free on our account.
import polars as pl
import coiled
def load_data():
# Define the S3 path and storage options and load the data into memory
s3_path = 's3://coiled-datasets/uber-lyft-tlc/*'
storage_options = {"aws_region": "us-east-2"}
return pl.scan_parquet(s3_path, storage_options=storage_options)
def compute_percentage_of_tipped_rides(lazy_df):
# Compute the percentage of rides with a tip for each license number
result = (lazy_df
.with_columns((pl.col("tips") > 0).alias("tipped"))
.group_by("hvfhs_license_num")
.agg([
(pl.sum("tipped") / pl.count("tipped")).alias("percentage_tipped")
]))
return result.collect()
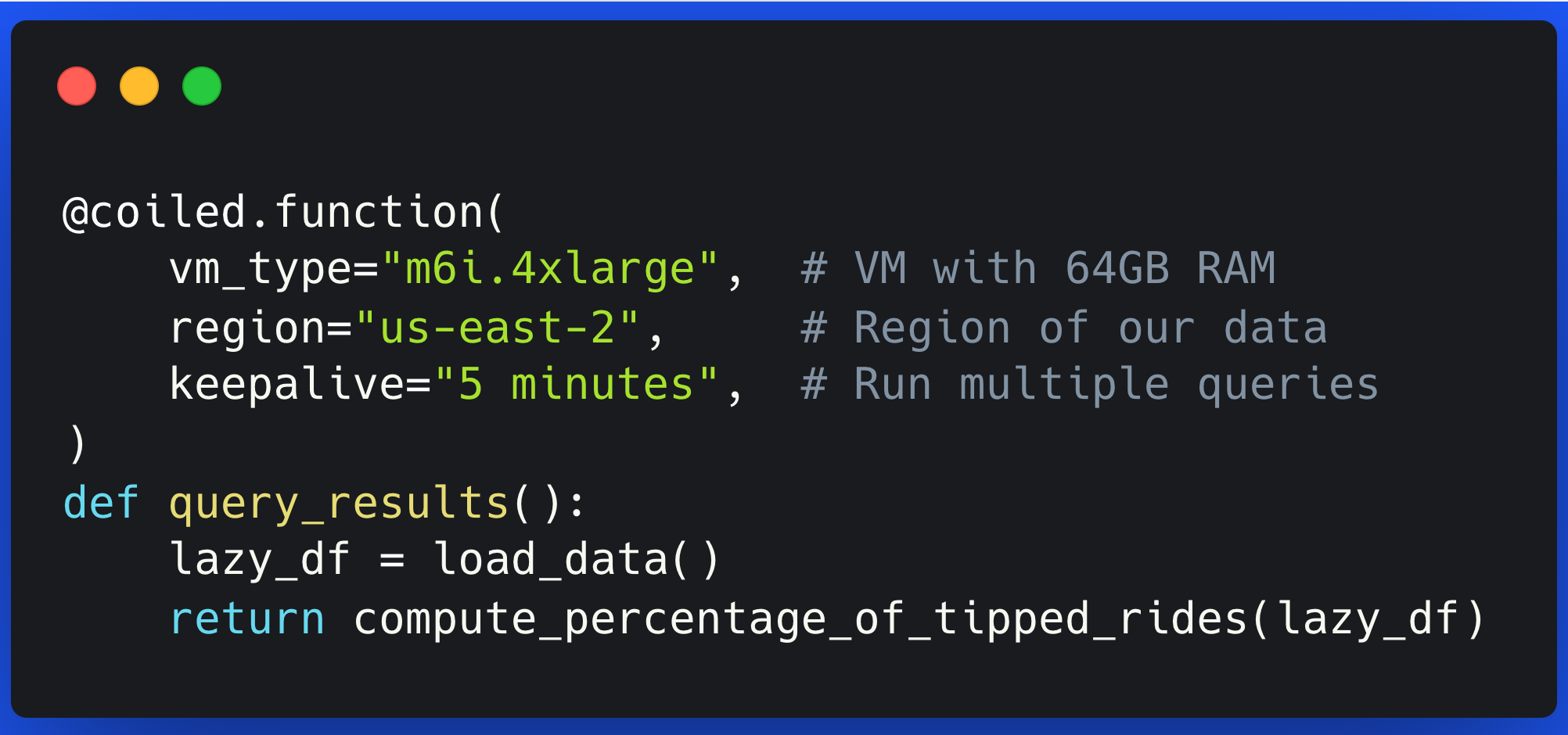
@coiled.function(
vm_type="m6i.4xlarge", # VM with 64GB RAM
region="us-east-2", # AWS region to match the data location
keepalive="5 minutes", # VM keepalive time for potential subsequent queries
)
def query_results():
# Load and process the dataset to compute the results
lazy_df = load_data()
return compute_percentage_of_tipped_rides(lazy_df)
# Run the query
result = query_results()
print(result)
import polars as pl
import coiled
def load_data():
# Define the S3 path and storage options and load the data into memory
s3_path = 's3://coiled-datasets/uber-lyft-tlc/*'
storage_options = {"aws_region": "us-east-2"}
return pl.scan_parquet(s3_path, storage_options=storage_options)
def compute_percentage_of_tipped_rides(lazy_df):
# Compute the percentage of rides with a tip for each license number
result = (lazy_df
.with_columns((pl.col("tips") > 0).alias("tipped"))
.group_by("hvfhs_license_num")
.agg([
(pl.sum("tipped") / pl.count("tipped")).alias("percentage_tipped")
]))
return result.collect()
@coiled.function(
vm_type="m6i.4xlarge", # VM with 64GB RAM
region="us-east-2", # AWS region to match the data location
keepalive="5 minutes", # VM keepalive time for potential subsequent queries
)
def query_results():
# Load and process the dataset to compute the results
lazy_df = load_data()
return compute_percentage_of_tipped_rides(lazy_df)
# Run the query
result = query_results()
print(result)
After you've run this code, we'll examine what happened section by section to understand how it works.
The Problem#
Processing large datasets locally presents several challenges:
- Memory Limits: The 150 GB Uber-Lyft dataset exceeds most laptops' RAM
- Network Bottlenecks: Downloading large datasets is slow
- Data Egress Costs: Moving data from cloud storage to local machines incurs fees
- Infrastructure Management: Setting up powerful compute resources is complex
You could set up cloud infrastructure manually, but that requires configuring cloud instances, managing Python environments, handling data transfer, monitoring resource usage, and cleaning up when done.
Instead, we'll use Coiled Functions to run our Polars queries directly in the cloud where the data lives.
The Solution#
Our approach consists of three main parts:
1. Loading Data#
We use Polars' lazy evaluation to scan Parquet files from S3 without loading everything into memory at once:
def load_data():
s3_path = 's3://coiled-datasets/uber-lyft-tlc/*'
storage_options = {"aws_region": "us-east-2"}
return pl.scan_parquet(s3_path, storage_options=storage_options)
def load_data():
s3_path = 's3://coiled-datasets/uber-lyft-tlc/*'
storage_options = {"aws_region": "us-east-2"}
return pl.scan_parquet(s3_path, storage_options=storage_options)
2. Query Processing#
We define a function that computes the percentage of rides with tips for each operator:
def compute_percentage_of_tipped_rides(lazy_df):
result = (lazy_df
.with_columns((pl.col("tips") > 0).alias("tipped"))
.group_by("hvfhs_license_num")
.agg([
(pl.sum("tipped") / pl.count("tipped")).alias("percentage_tipped")
]))
return result.collect()
def compute_percentage_of_tipped_rides(lazy_df):
result = (lazy_df
.with_columns((pl.col("tips") > 0).alias("tipped"))
.group_by("hvfhs_license_num")
.agg([
(pl.sum("tipped") / pl.count("tipped")).alias("percentage_tipped")
]))
return result.collect()
3. Cloud Execution#
We use the @coiled.function decorator to run our query in the cloud:
@coiled.function(
vm_type="m6i.4xlarge", # VM with 64GB RAM
region="us-east-2", # AWS region to match the data location
keepalive="5 minutes", # VM keepalive time for subsequent queries
)
def query_results():
lazy_df = load_data()
return compute_percentage_of_tipped_rides(lazy_df)
@coiled.function(
vm_type="m6i.4xlarge", # VM with 64GB RAM
region="us-east-2", # AWS region to match the data location
keepalive="5 minutes", # VM keepalive time for subsequent queries
)
def query_results():
lazy_df = load_data()
return compute_percentage_of_tipped_rides(lazy_df)
The decorator handles all infrastructure details:
- Starting a powerful cloud VM
- Running the VM in the same region as the data
- Setting up your Python environment
- Running your code
- Returning just the results
- Cleaning up automatically
Results#
With this approach, we achieved impressive results:
- Processed 150 GB of data in ~7 minutes
- Ran in the same region as the data (no egress costs)
- Used a VM with sufficient RAM (no memory issues)
- Avoided all infrastructure management
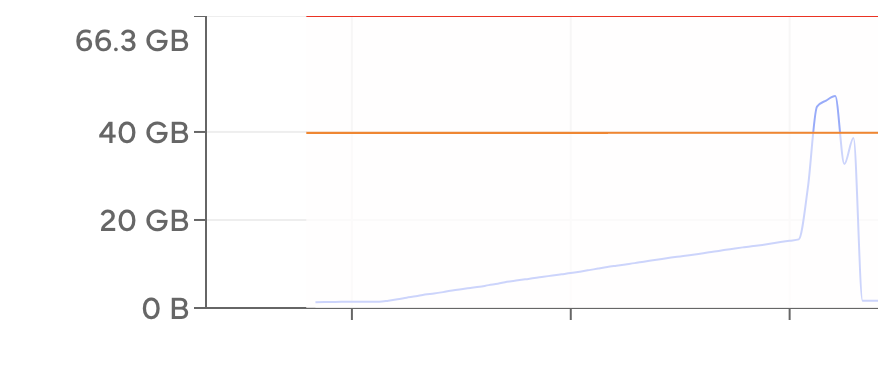
The VM started in about 2 minutes, and the actual computation took about 5 minutes. The memory utilization graph showed efficient use of the available RAM.
Our query returned the percentage of rides that received tips for each service:
[
('HV0002', 0.08440046492889111),
('HV0003', 0.1498555901186066),
('HV0004', 0.09294857737045926),
('HV0005', 0.1912300216459857),
]
[
('HV0002', 0.08440046492889111),
('HV0003', 0.1498555901186066),
('HV0004', 0.09294857737045926),
('HV0005', 0.1912300216459857),
]
Next Steps#
Here are a few ways you could extend this example:
- Try different VM sizes to see how they affect performance. For example, use a larger VM like
m6i.8xlargefor even faster processing. - Process different datasets by changing the S3 path in the
load_datafunction. - Modify the query to answer different questions about the data, such as analyzing ride patterns by time of day.
- Use warmer VMs by increasing the
keepaliveparameter to avoid startup time for subsequent queries.
For processing even larger datasets, you could scale up to a more powerful VM:
@coiled.function(
vm_type="m6i.16xlarge", # VM with 256GB RAM
region="us-east-2", # Same region as data
keepalive="1 hour", # Keep VM alive longer
)
def big_query():
# Process even larger datasets
...
@coiled.function(
vm_type="m6i.16xlarge", # VM with 256GB RAM
region="us-east-2", # Same region as data
keepalive="1 hour", # Keep VM alive longer
)
def big_query():
# Process even larger datasets
...
Get started
Know Python? Come use the cloud. Your first $25 of usage per month is on us.
$ pip install coiled
$ coiled quickstart
Grant cloud access? (Y/n): Y
... Configuring ...
You're ready to go. 🎉$ pip install coiled
$ coiled quickstart
Grant cloud access? (Y/n): Y
... Configuring ...
You're ready to go. 🎉